Cómo medí el Click-Through Rate de mi currículum
El silencio de la búsqueda de empleo
Si has buscado trabajo alguna vez, conoces la sensación: preparas tu currículum, lo adaptas a la empresa, lo envías… y entras en un agujero negro. No sabes si alguien lo ha abierto, si lo han leído entero o si ha acabado directamente en una carpeta de descartados. La falta de feedback real convierte el proceso en algo oscuro y, francamente, frustrante. Tomas decisiones (qué destacar, cómo ordenar tu experiencia, qué proyectos enlazar) completamente a ciegas, sin ninguna señal de si funcionan.
Ese vacío de información fue el punto de partida de este proyecto. No buscaba vigilar a nadie ni obtener datos personales; buscaba lo mismo que busca cualquiera que itera sobre un producto: una señal que me dijera si lo que estoy haciendo conecta o no.
Una métrica prestada del email marketing
En el mundo del email marketing este problema está resuelto desde hace décadas con dos métricas clásicas.
La primera es la tasa de apertura (open rate): el porcentaje de personas que abren un correo. Es un termómetro excelente de lo bien que funcionan el asunto del email y sus dos primeras líneas, porque eso es lo único que el destinatario ve antes de decidir si abre o ignora.
La segunda es la tasa de clics (Click-Through Rate, o CTR): el porcentaje de personas que, una vez dentro, hacen clic en alguno de los enlaces del mensaje. El CTR mide algo más profundo que la apertura: mide interés real. Abrir un correo cuesta un instante; hacer clic en un enlace implica que algo te ha llamado lo suficiente la atención como para querer profundizar.
La idea de este proyecto es sencilla de enunciar: recrear esas métricas para aplicarlas a la búsqueda de empleo. Plataformas como LinkedIn ya ofrecen algo así: cuando envías una candidatura con Easy Apply, te notifican si el reclutador la ha visto e incluso si ha descargado tu CV. Es, de hecho, una tasa de apertura regalada. El problema es que vive presa de su propio jardín amurallado: solo funciona con candidaturas nativas de LinkedIn, no te dice quién la vio exactamente, y en cuanto el proceso se mueve a la plataforma propia de la empresa o a un sistema de terceros, esa visibilidad desaparece por completo. Yo quería una señal que fuera mía, independiente de la plataforma por la que llegara mi candidatura.
Por qué el PDF es un callejón sin salida
Aquí aparece el primer muro. El currículum se envía, casi siempre, como un PDF: es cómodo, se ve igual en cualquier dispositivo y es el formato que todo el mundo espera recibir. El problema es que el PDF es, por diseño, un documento cerrado y estático, terriblemente difícil de instrumentar. Antes de construir nada, investigué qué métodos existen para rastrear un PDF, y casi todos se topan con el mismo tipo de barrera.
El método clásico es el píxel de seguimiento: una imagen diminuta (a menudo de 1×1, oculta tras el texto) que el documento descarga desde tu servidor en el momento en que se abre, registrando así la “apertura”. Es la técnica que sostiene la tasa de apertura del email marketing, y técnicamente también se puede incrustar en un PDF. El problema es que dentro de un PDF se vuelve muy poco fiable por razones propias del formato. Los visores web (los de Gmail, Google Drive o la previsualización del navegador, además de muchos portales de RRHH) no cargan contenido externo por defecto, así que el píxel nunca llega a dispararse. Y los lectores de escritorio que sí podrían cargarlo, como Adobe Acrobat, suelen pedir permiso explícito antes de conectarse a un dominio externo: ese aviso de “¿permitir que este documento se conecte a internet?” no solo arruina la fiabilidad de la medición, sino que delata al destinatario que el PDF lo está vigilando. Entre los visores que ignoran la imagen y los que alertan al lector, una métrica de apertura basada en un píxel acaba siendo, en el mejor de los casos, ruido.
Pero hay una razón aún más contundente para no ir por ahí. Las técnicas que harían que un PDF “llame a casa” al abrirse (cargar una imagen remota o ejecutar un pequeño script) son exactamente las mismas que emplea el malware para filtrar datos o rastrear víctimas. Por eso los escáneres de seguridad de correo y los antivirus corporativos las detectan y las marcan como sospechosas. Dicho de otro modo: intentar medir la apertura del PDF no solo es poco fiable, sino que arriesga a que mi currículum acabe en la carpeta de spam o sea descartado directamente como un adjunto peligroso. El precio de un dato dudoso es demasiado alto.
La alternativa fiable es no enviar el PDF en absoluto, sino alojarlo tras una landing page o un visor propio (es lo que hacen herramientas como Adobe Send & Track o DocSend). Esto da analíticas muy ricas (incluso página a página), pero a costa de una fricción enorme: obligas al destinatario a no descargar el archivo, a veces a registrarse, y a leer tu currículum dentro de tu visor. Para un reclutador que recibe decenas de candidaturas, cualquier fricción es motivo de abandono.
La conclusión de esa investigación fue clarificadora: la tasa de apertura de un PDF es prácticamente inalcanzable de forma limpia y discreta. No hay manera sólida y cross-platform de saber si alguien abrió el documento sin recurrir a técnicas invasivas que los visores modernos bloquean o exponen al lector. Así que decidí dejar de pelear contra esa pared y centrarme en lo único que sí es medible de forma fiable: el clic.
Mi enfoque: redirigir cada enlace a través de una web propia
Un currículum técnico está lleno de enlaces: el repositorio de GitHub, la grabación de una charla, el perfil de LinkedIn, una publicación. Cada uno de esos enlaces es una oportunidad de medir interés. Y, a diferencia de la apertura del documento, un clic sí puedo capturarlo de forma fiable, porque un clic ocurre en un navegador web, que es justo el terreno donde las herramientas de analítica funcionan bien.
La idea central es no enlazar nunca directamente al destino final. En lugar de que el botón de “GitHub” apunte a github.com, apunta a una página intermedia alojada en mi propia web. Cuando alguien hace clic, su navegador carga esa página, que dispara un evento de analítica y, acto seguido, lo redirige al destino real. Para el destinatario la experiencia es casi transparente (ve una fracción de segundo de “Redirigiendo…” y llega a donde quería), pero para mí ese paso intermedio es donde se registra el clic.
Para distinguir el tráfico de mi currículum de cualquier otra visita, añado a cada enlace un conjunto de parámetros UTM, el estándar que el marketing digital lleva usando años precisamente para atribuir tráfico:
?utm_source=VAR_CLIENTE&utm_medium=pdf&utm_campaign=cv
Cada parámetro cuenta una parte de la historia. El utm_campaign=cv marca el tráfico como perteneciente a la campaña del currículum, para poder aislarlo de todo lo demás. El utm_medium=pdf identifica el canal por el que viajó el enlace: un documento PDF. Y el más importante, utm_source, lleva el nombre de la empresa o persona a la que envié esa copia concreta del CV. Ese VAR_CLIENTE es un marcador de posición que se reemplaza por algo como empresa_ejemplo antes de enviar cada versión.
La consecuencia es poderosa: en el panel de analítica no solo veo cuántos clics ha recibido mi currículum, sino que puedo atribuir cada clic a un destinatario concreto. Es exactamente la granularidad que una plataforma de email marketing te da de serie, pero construida sobre un PDF que viaja por cualquier canal.
Hubo un caso que me obligó a pensar un poco más. Para enlaces fijos (mi LinkedIn, una charla concreta) basta con una página intermedia por destino. Pero los proyectos de GitHub son muchos y cambiantes, y no quería crear una página redirectora distinta para cada repositorio. La solución fue una única página dinámica: en lugar de tener un destino fijo, lee un parámetro adicional (utm_content) de la propia URL y construye el destino al vuelo. Así, un enlace como …/a/project?...&utm_content=org/mi-proyecto redirige a github.com/org/mi-proyecto, y la misma página sirve para cualquier número de repositorios. Esto, de paso, resuelve una limitación que otros proyectos parecidos reconocen tener: poder medir también los clics hacia plataformas externas, no solo hacia páginas propias.
Automatizar la generación de cada CV
Hay un detalle práctico que, sin resolver, habría hecho inviable todo el sistema. Mi currículum tiene más de quince enlaces, y el utm_source de cada uno debe cambiar para cada empresa a la que envío el documento. Hacer eso a mano (abrir un editor de PDF, localizar cada hiperenlace y reescribir su URL uno por uno) es tedioso, propenso a errores y no escala lo más mínimo.
Por eso escribí un pequeño script en Python que automatiza el proceso por completo. Usa la librería pikepdf, un binding sobre el motor QPDF que permite manipular PDFs a bajo nivel. El script parte de una plantilla del currículum, recorre todas sus páginas e inspecciona las anotaciones de cada una (la estructura interna del PDF que representa los hiperenlaces). Por cada enlace cuya URL contiene el marcador VAR_CLIENTE, sustituye ese marcador por el nombre del destinatario y guarda el resultado como un PDF nuevo, dejando la plantilla original intacta y lista para el siguiente envío.
El núcleo del proceso es tan simple como esto:
import pikepdf
pdf = pikepdf.Pdf.open("data/cv_template.pdf")
for page in pdf.pages:
if "/Annots" in page:
for annot in page["/Annots"]:
if "/A" in annot and "/URI" in annot["/A"]:
uri = str(annot["/A"]["/URI"])
if "VAR_CLIENTE" in uri:
annot["/A"]["/URI"] = uri.replace("VAR_CLIENTE", empresa)
pdf.save(f"data/CV_{empresa.capitalize()}.pdf")
Le paso el nombre de la empresa como argumento, y en un segundo tengo un PDF personalizado y listo para enviar, con sus quince enlaces correctamente etiquetados. El script además me informa de cuántos enlaces ha actualizado, lo que me sirve de comprobación rápida de que no se ha quedado ninguno por el camino. Lo que antes era una tarea manual de varios minutos pasa a ser instantáneo.
Visualizando los datos en Google Analytics
Recoger los clics es solo la mitad del trabajo; la otra mitad es leerlos. Para esto uso Google Analytics 4 (GA4), donde cada visita a una de mis páginas intermedias llega ya etiquetada con sus parámetros UTM. El reto es que los informes estándar de GA4 no permiten cruzar con comodidad la fuente (utm_source) con el tiempo, que es justo lo que me interesa: quién hizo clic, cuándo y donde.
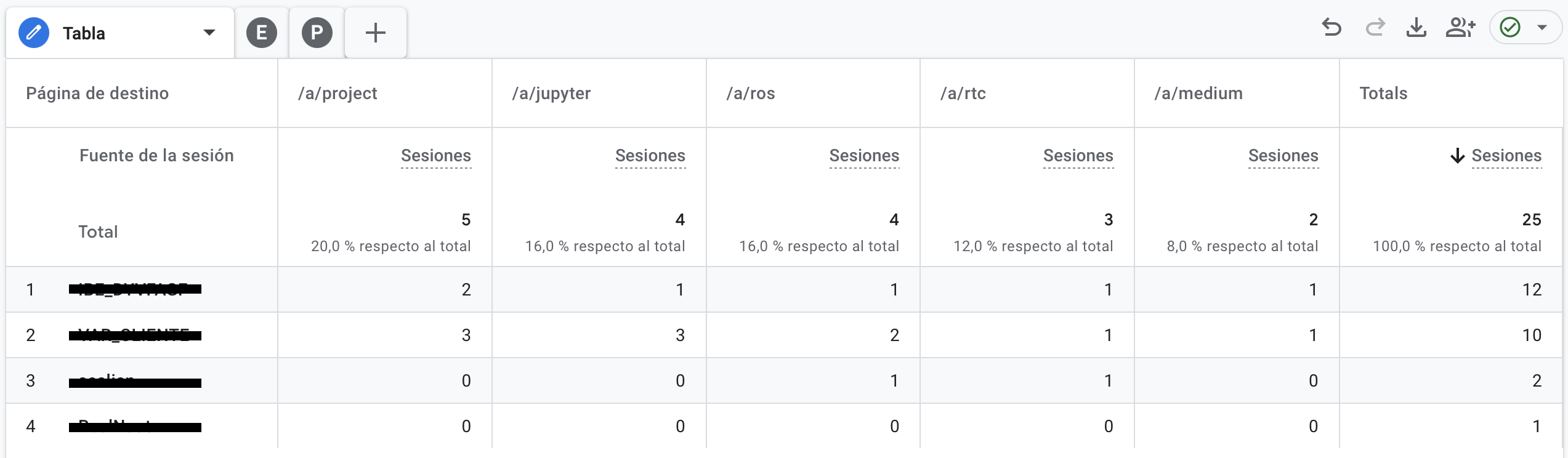
La herramienta adecuada para esto es Exploraciones (Explore), el módulo de GA4 pensado para análisis a medida. Creé una exploración en blanco y añadí como dimensiones la fuente de la sesión (que recoge el valor de utm_source, es decir, el nombre de la empresa), la campaña y el medio de la sesión (para poder filtrar), y la fecha. Como métrica, el número de sesiones. Después monté una tabla cruzada con la fuente en las filas y la fecha en las columnas, de modo que cada celda muestra cuántos clics llegó de una empresa concreta en un día concreto. El último paso es un filtro que deja fuera todo lo que no pertenezca a la campaña del currículum: campaña = cv y medio = pdf. El resultado es una matriz que responde de un vistazo a la pregunta que dio origen al proyecto.
Límites y honestidad intelectual
Sería deshonesto presentar esto como un sistema infalible, así que conviene ser claro sobre lo que no hace.
Lo primero y más evidente: no mide la apertura del documento. Por todo lo que conté antes, sé si alguien hizo clic, pero no si abrió el PDF y no hizo clic en nada. Un currículum puede leerse de principio a fin sin tocar un solo enlace, y ese lector, para mí, es invisible. El CTR es una señal de interés, no un censo de lectores.
Segundo, y más sutil: los bots inflan las métricas. Muchas empresas pasan los enlaces entrantes por escáneres de seguridad (sistemas como Microsoft Defender SafeLinks) que visitan automáticamente cada URL para comprobar que no es maliciosa, antes de que ningún humano la vea. Para mi página intermedia, esa visita automática es indistinguible de un clic real, lo que significa que algunos de los “clics” que registro nunca correspondieron a una persona. Hay que leer los datos como una señal direccional, no como una verdad literal: un pico de actividad desde una empresa es informativo, pero un único registro aislado podría ser perfectamente un escáner.
Tercero, hay una dimensión ética y de privacidad que no quiero pasar por alto. Esto funciona porque los parámetros UTM son un estándar abierto y transparente, no un exploit; cualquiera que mire la URL puede ver exactamente qué se está midiendo. No recojo datos personales, ni ubicaciones precisas, ni nada que el destinatario no exponga voluntariamente al hacer clic en un enlace público. Es la misma tecnología que sostiene prácticamente todo el marketing digital de la web.
Por último, vale la pena decir que no soy el primero al que se le ocurre esto. Mientras investigaba encontré a más gente recorriendo este mismo camino: el caso más cercano es el de Adam, en datatribute.com, que construyó un script en Python para generar versiones de su CV con enlaces etiquetados por empresa y medirlas en GA4, casi idéntico al mío. Curiosamente, él reconoce como limitación que solo podía medir clics hacia páginas de su propiedad, no hacia plataformas externas como GitHub: justo el problema que resuelve mi página redirectora dinámica.
Cierre
Este proyecto no me dice quién va a contratarme, ni siquiera quién ha leído mi currículum entero. Lo que me da es algo más modesto y, a la vez, más útil de lo que parece: una pequeña ventana de feedback en un proceso diseñado para no dártelo. Saber que una empresa concreta hizo clic en la grabación de una charla, o que otra entró a un repositorio en cuestión de minutos tras recibir el CV, transforma la búsqueda de empleo de un monólogo a ciegas en algo que, al menos en parte, puedo medir e iterar.
Y, en el fondo, de eso trataba todo: de convertir el silencio en una señal.